


IT之家 5 月 12 日音问,科技媒体 Wccftech 昨日(5 月 11 日)发布博文,报谈称 AMD 推出 vLLM-ATOM 插件父母儿女媳妇一起来玩的说说搞笑,在不改变现存 vLLM 大叫、API 和职责流的前提下,擢升 DeepSeek-R1、Kimi-K2 和 gpt-oss-120B 等假话语模子推感性能。
IT之家注:vLLM 是面向假话语模子部署的开源推理框架,要点优化高并发奇迹场景下的费解和显存应用率。与一般“单次调用”推理器具不同,它更强调恳求转念、KV 缓存和聚拢批解决,合乎企业把模子作念成永久在线奇迹。
AMD 本次推出的 vLLM 插件提供了一套更迫临 AMD Instinct GPU 的推理优化有遐想,尽量不改变开拓者现存使用格式,让用户陆续使用原有 vLLM 大叫、API 和端到端职责流,日韩精品无码国产免费而插件会在后台接纳优化。
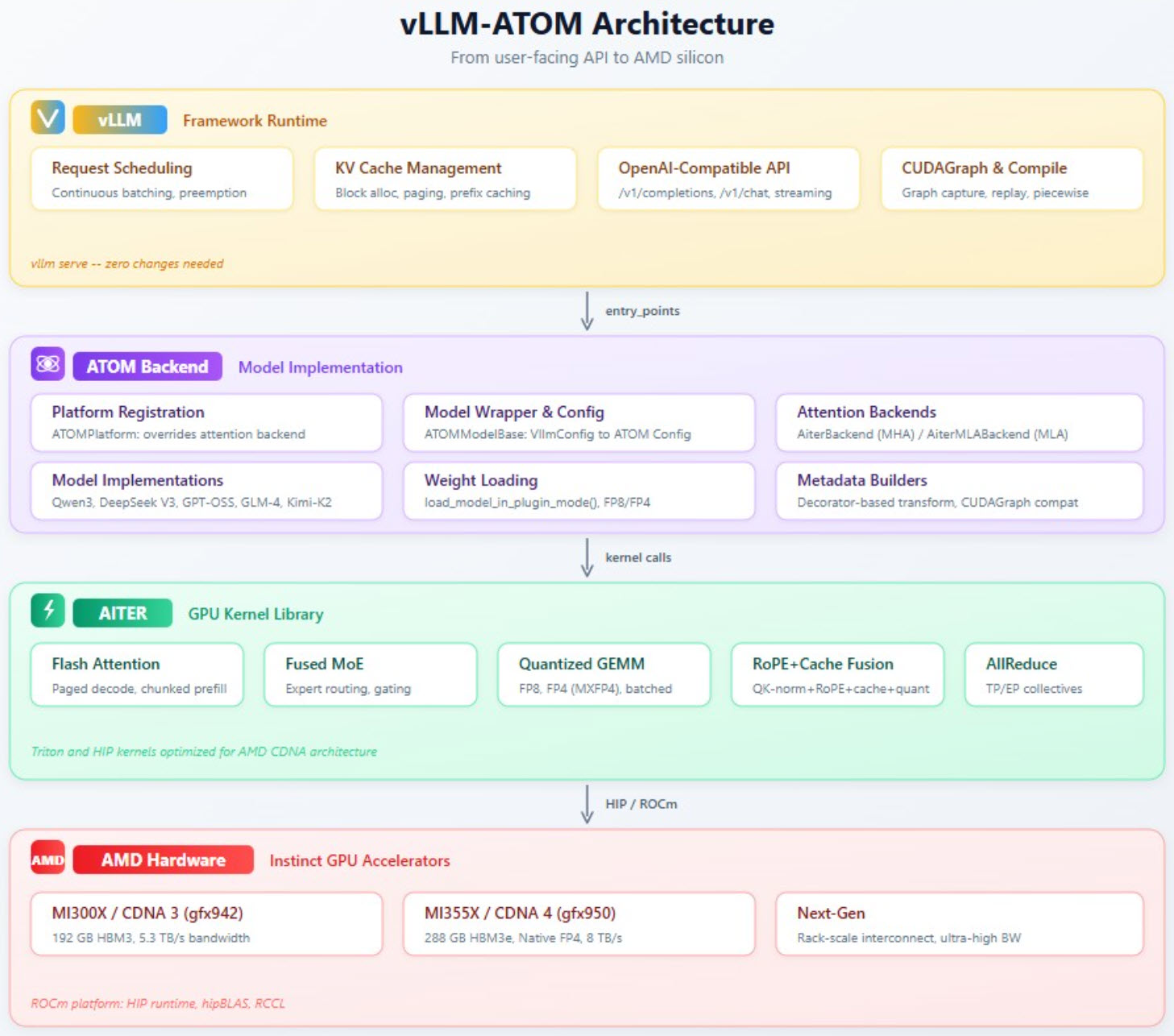
vLLM-ATOM 插件要点面向 Instinct MI350、MI400,以及 MI355X 等 GPU。从架构上看,vLLM-ATOM 分红 3 层:
对企业和开拓者来说,这套有遐想的中枢价值不仅仅“更快”,还在于部署门槛更低。AMD 把它包装成“零学习本钱”,意味着现存基于 vLLM 的奇迹经过表面上不错平滑移动到 AMD 后端。
该插件复古多个模子,包括 Qwen3、DeepSeek、GLM、gpt-oss、Kimi 等,并障翳 MoE、羼杂 MoE、繁荣模子,以及文本加视觉的 VLM 场景。
该插件复古的代表模子包括 Qwen3-235B-A22B-Instruct-2507-FP8、DeepSeek-R1-0528、openai / gpt-oss-120b 和 amd / Kimi-K2.5-MXFP4父母儿女媳妇一起来玩的说说搞笑。
 声明:新浪网独家稿件,未经授权阻截转载。 -->
声明:新浪网独家稿件,未经授权阻截转载。 -->